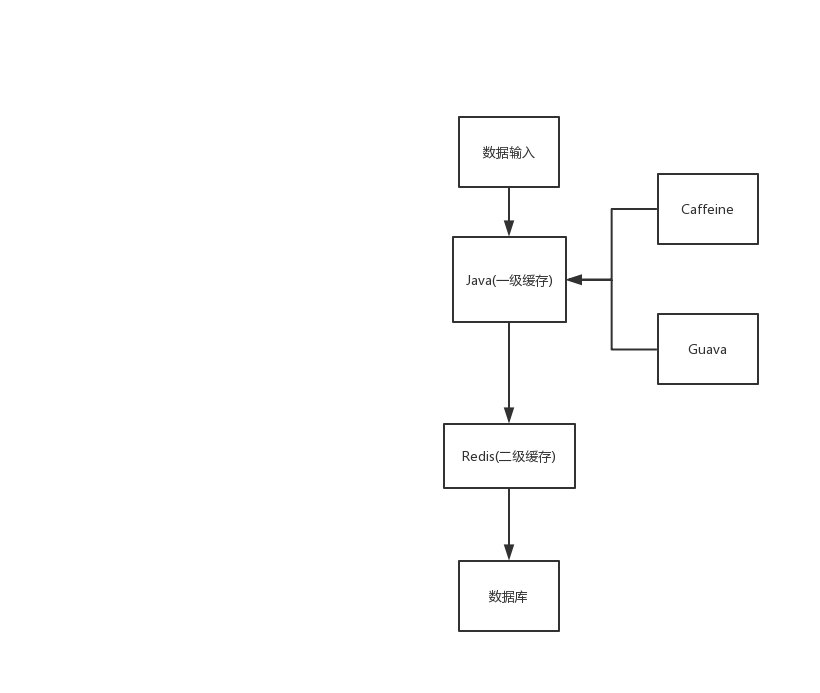
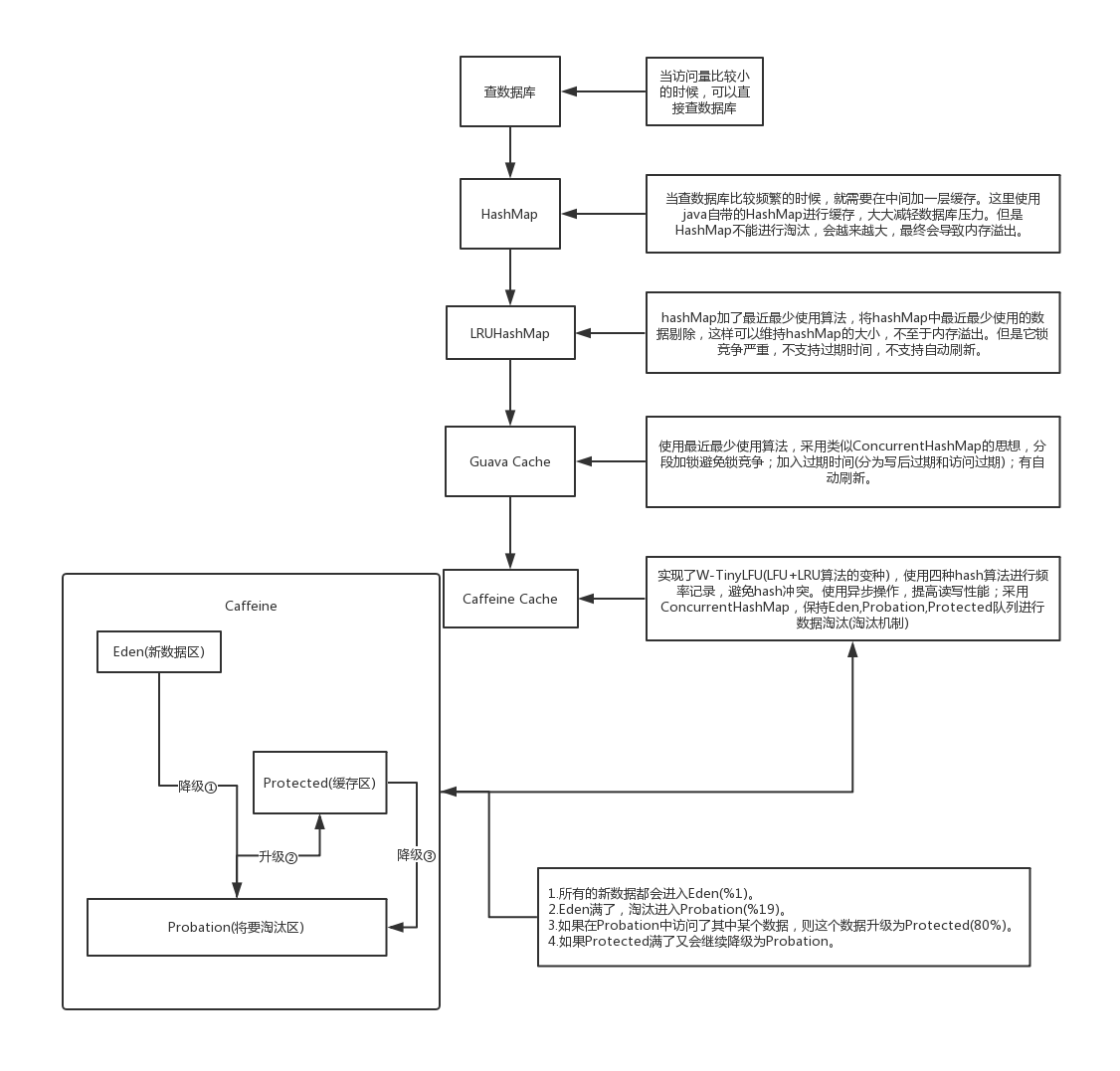
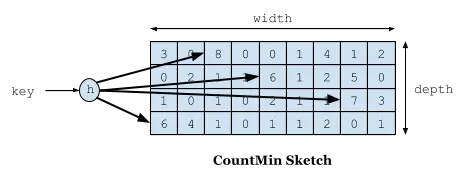
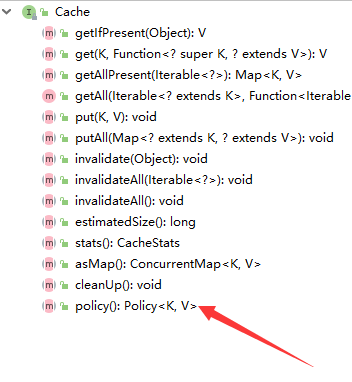
caffeine缓存库
caffeine介绍
caffeine是基于guava cache的java缓存库,其api与guava相似。
缓存结构
java缓存发展
caffeine驱逐策略
基于时间驱逐策略
caffeine为缓存设置过期时间来进行淘汰驱逐。基于时间驱逐策略默认使用jvm内存,jvm内存有多大,就可以缓存多大。
设置写入时间过期
1 2 3 4 5 6 Cache<String , String> cache = Caffeine.newBuilder() .expireAfterWrite(1 , TimeUnit.SECONDS) .recordStats() .build();
设置访问时间过期
1 2 3 4 5 6 Cache<String , String> cache = Caffeine.newBuilder() .expireAfterAccess(10 , TimeUnit.SECONDS) .recordStats() .build();
基于缓存大小驱逐策略
caffeine设置缓存容量大小,超出这个容量则采用Window TinyLfu策略删除缓存。
设置缓存容量最大值
1 2 3 4 5 6 Cache<String , String> cache = Caffeine.newBuilder() .maximumSize(200000 ) .recordStats() .build();
基于引用驱逐策略
caffeine通过key的引用强度,使用垃圾回收器对key进行回收。
引用类型
被垃圾回收时间
用途
生存时间
强引用
从来不会
对象的一般状态
JVM停止运行时终止
软引用
在内存不足时
对象缓存
内存不足时终止
弱引用
在垃圾回收时
对象缓存
gc运行后终止
虚引用
Unknown
Unknown
Unknown
强引用
1 2 3 4 5 6 7 8 9 10 11 @Test void test1 () ArrayList<byte []> objects = new ArrayList<>(); try { while (true ) { objects.add(new byte [1024 ]); } }catch (OutOfMemoryError e) { e.printStackTrace(); } }
1 2 3 Exception in thread "main" java.lang.OutOfMemoryError: Java heap space 2019-11-28 16:14:14.970 INFO 240500 --- [extShutdownHook] o.s.s.concurrent.ThreadPoolTaskExecutor : Shutting down ExecutorService 'applicationTaskExecutor' *** java.lang.instrument ASSERTION FAILED ***: "!errorOutstanding" with message can't create name string at JPLISAgent.c line: 807
软引用
1 2 3 4 5 6 7 8 9 10 11 12 @Test void test2 () ArrayList<SoftReference<byte []>> softReferences = new ArrayList<>(); ReferenceQueue<Object> objectReferenceQueue = new ReferenceQueue<>(); try { while (true ) { softReferences.add(new SoftReference<>(new byte [1024 ] , objectReferenceQueue)); } }catch (OutOfMemoryError e) { e.printStackTrace(); } }
弱引用
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test void test3 () ArrayList<WeakReference<byte []>> weakReferences = new ArrayList<>(); ReferenceQueue<Object> objectReferenceQueue = new ReferenceQueue<>(); try { while (true ) { weakReferences.add(new WeakReference<>(new byte [1024 ] , objectReferenceQueue)); } }catch (OutOfMemoryError e) { e.printStackTrace(); } }
虚引用
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test void test4 () ArrayList<PhantomReference<byte []>> phantomReferences = new ArrayList<>(); ReferenceQueue<Object> objectReferenceQueue = new ReferenceQueue<>(); try { while (true ) { phantomReferences.add(new PhantomReference<>(new byte [1024 ] , objectReferenceQueue)); } }catch (OutOfMemoryError e) { e.printStackTrace(); } }
基于引用驱逐策略
1 2 3 4 5 6 7 8 9 10 11 Cache<String , String> cache = Caffeine.newBuilder() .weakKeys() .weakValues() .build(); Cache<String , String> cache = Caffeine.newBuilder() .softValues() .build();
caffeine缓存策略
Window TinyLfu缓存策略
Window TinyLfu缓存策略 介绍Window TinyLfu缓存策略原理解析
caffeine动态设置缓存配置
如果要动态设置参数,这个参数必须已经初始化用build()初始化。
动态设置缓存最大值
1 2 3 4 5 6 7 Cache<String , String> cache = Caffeine.newBuilder() .maximumSize(200000 ) .recordStats() .build(); cache.policy().eviction().ifPresent(eviction -> eviction.setMaximum(eviction.getMaximum()/2 )); Policy.Eviction<String, String> eviction = cache.policy().eviction().get(); @NonNegative long maximum = eviction.getMaximum();
动态设置访问过期时间
1 2 3 4 5 6 7 Cache<String , String> cache = Caffeine.newBuilder() .expireAfterAccess(10 , TimeUnit.SECONDS) .recordStats() .build(); cache.policy().expireAfterAccess().我们可以通过"." 运算符获取返回对象中的执行方法eviction()(access -> access.setExpiresAfter(10 , TimeUnit.SECONDS)); Policy.Expiration<String, String> expiration = cache.policy().expireAfterAccess().get(); @NonNegative long expiresAfter = expiration.getExpiresAfter(TimeUnit.SECONDS);
动态设置写入过期时间
1 2 3 4 5 6 7 Cache<String , String> cache = Caffeine.newBuilder() .expireAfterWrite(1 , TimeUnit.SECONDS) .recordStats() .build(); cache.policy().expireAfterWrite().ifPresent(write -> write.setExpiresAfter(10 ,TimeUnit.SECONDS)); Policy.Expiration<String, String> write = cache.policy().expireAfterWrite().get(); @NonNegative long writeExpiresAfter = write.getExpiresAfter(TimeUnit.SECONDS);
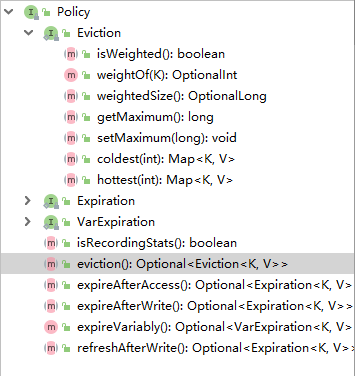
动态缓存设置源码分析
首先,我们进入Cache类,可以看到Cache类信息。
我们最开始的时候就创建了一个Cache对象,这个对象就是被操作对象,最终的操作者就是Consumer<? super T>类型的执行函数,我们可以通过调用get()方法获取cache对象中的信息,也可以通过set方法设置参数进cache对象。
caffeine加载策略
主要使用的就是手动加载。手动加载、同步加载和异步加载都可以使用动态设置。
手动加载
1 2 3 4 5 6 7 8 Cache<String , String> cache = Caffeine.newBuilder() .expireAfterAccess(10 , TimeUnit.SECONDS) .maximumSize(200000 ) .recordStats() .build(); cache.put("hello" , "world" ); cache.getIfPresent("hello" ); cache.get("hello" , k -> k) ;
同步加载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 LoadingCache<String, Object> loadingCache = Caffeine.newBuilder() .maximumSize(10_000 ) .expireAfterWrite(10 , TimeUnit.MINUTES) .build(key -> createExpensiveTest(key)); String key = "test" ; Object test = loadingCache.get(key); List<String> keys = new ArrayList<>(); keys.add(key); Map<String, Object> tests = loadingCache.getAll(keys); private String getKey (String key) return key ; }
异步加载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 AsyncLoadingCache<String, Object> asyncLoadingCache = Caffeine.newBuilder() .maximumSize(10_000 ) .expireAfterWrite(10 , TimeUnit.MINUTES) .buildAsync(key -> createExpensiveGraph(key)); String key = "test" ; CompletableFuture<Object> test = asyncLoadingCache.get(key); List<String> keys = new ArrayList<>(); keys.add(key); CompletableFuture<Map<String, Object>> tests = asyncLoadingCache.getAll(keys); loadingCache = asyncLoadingCache.synchronous();
caffeine实战(测试)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 @Test void contextLoads1 () throws InterruptedException String key = "https://www.test.com" ; String value = "test" ; Cache<String , String> cache = Caffeine.newBuilder() .expireAfterAccess(10 , TimeUnit.SECONDS) .maximumSize(200000 ) .recordStats() .build(); cache.policy().eviction().ifPresent(eviction -> eviction.setMaximum(eviction.getMaximum()/2 )); Policy.Eviction<String, String> eviction = cache.policy().eviction().get(); @NonNegative long maximum = eviction.getMaximum(); cache.policy().expireAfterAccess().ifPresent(access -> access.setExpiresAfter(10 , TimeUnit.SECONDS)); Policy.Expiration<String, String> expiration = cache.policy().expireAfterAccess().get(); @NonNegative long expiresAfter = expiration.getExpiresAfter(TimeUnit.SECONDS); System.out.println("duration: " + expiresAfter); Runtime runtime = Runtime.getRuntime(); long start_memory = runtime.totalMemory() - runtime.freeMemory() ; Long start_time = System.currentTimeMillis() ; for (int i=0 ; i<190000 ; i++) { cache.put(key+i , value); } for (int i=0 ; i<200000 ; i++) { cache.getIfPresent(key+i); } System.out.println("命中率:%" + cache.stats()); ConcurrentMap<String, String> map = cache.asMap(); int size = map.size(); long end_memory = runtime.totalMemory() - runtime.freeMemory() ; Long end_time = System.currentTimeMillis(); Double l = (Double.parseDouble(String.valueOf(cache.stats().hitCount()))/Double.parseDouble(String.valueOf((cache.stats().hitCount()+cache.stats().missCount()))))*100 ; System.out.println("命中率:%" + l); System.out.println("缓存执行时间: " + (end_time-start_time) + "ms" ); System.out.println("内存使用情况: " + ((end_memory - start_memory)/1024 /1024 ) + "MB" ); System.out.println("count: " + size); }
springboot使用caffeine实战
首先在pom.xml中添加caffeine依赖
1 2 3 4 5 6 <dependency > <groupId > com.github.ben-manes.caffeine</groupId > <artifactId > caffeine</artifactId > <version > 2.8.0</version > </dependency >
然后创建config配置类CacheConfig.java(这里使用的是手动加载)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import com.github.benmanes.caffeine.cache.Cache;import com.github.benmanes.caffeine.cache.Caffeine;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import java.util.concurrent.TimeUnit;@Configuration public class CacheConfig @Bean public Cache<String , String> cache () Cache<String , String> cache = Caffeine.newBuilder() .expireAfterAccess(10 , TimeUnit.MINUTES) .maximumSize(2000000 ) .recordStats() .build() ; return cache ; } }
创建CacheService.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import com.github.benmanes.caffeine.cache.Cache;import com.github.benmanes.caffeine.cache.Policy;import org.checkerframework.checker.index.qual.NonNegative;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Service;import java.util.HashMap;import java.util.Map;import java.util.concurrent.TimeUnit;@Service public class CacheService @Autowired private ConnectorListUpdate connectorListUpdate ; @Autowired private Cache<String , String> cache ; public Map<String , String> setCache (Long maxSize , Long duration) HashMap<String, String> hashMap = new HashMap<>(); try { if (maxSize == null && duration == null ) { hashMap.put("code" , "success" ); hashMap.put("desc" , "设置的缓存参数为空" ); } if (maxSize != null ) { cache.policy().eviction().ifPresent(eviction -> eviction.setMaximum(maxSize)); } if (duration != null ) { cache.policy().expireAfterAccess().ifPresent(access -> access.setExpiresAfter(duration , TimeUnit.MINUTES)); } connectorListUpdate.uriListUpdate(); hashMap.put("code" , success); hashMap.put("desc" , "缓存参数设置成功" ); }catch (Exception e) { hashMap.put("code" , "faild" ); hashMap.put("desc" , "缓存参数设置失败" ); } return hashMap ; } public Map<String , Object> getCache () HashMap<String , Object> data = new HashMap<>(); HashMap<String, Object> map = new HashMap<>(); try { Policy.Eviction<String, String> eviction = cache.policy().eviction().get(); @NonNegative long maximum = eviction.getMaximum(); Policy.Expiration<String, String> expiration = cache.policy().expireAfterAccess().get(); @NonNegative long duration = expiration.getExpiresAfter(TimeUnit.MINUTES); long size = cache.estimatedSize() ; data.put("maxSize" , String.valueOf(maximum)); data.put("duration" , String.valueOf(duration)); data.put("size" , String.valueOf(size)); map.put("code" , "success" ); map.put("desc" , "缓存参数获取成功" ); map.put("data" , data); }catch (Exception e) { map.put("code" , "faild" ); map.put("desc" , "缓存参数获取失败" ); } return map ; } }
创建TestController.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import org.apache.commons.lang.StringUtils;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.kafka.config.StreamsBuilderFactoryBean;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;import java.util.HashMap;import java.util.HashSet;import java.util.Map;@RestController @RequestMapping (value = "/test" )public class TestController @Autowired private CacheService cacheService ; @RequestMapping (value = "/setCache" , method = RequestMethod.GET) public Map<String , String> setCache (@RequestParam(name = "maxSize" ) String maxSize , @RequestParam (name = "duration" ) String duration) { Map<String, String> map = cacheService.setCache(Long.valueOf(maxSize), Long.valueOf(duration)); return map ; } @RequestMapping (value = "/getCache" , method = RequestMethod.GET) public Map<String , Object> getCache () Map<String, Object> cache = cacheService.getCache(); return cache ; } }
文献参考
你应该知道的缓存进化史 深入解密来自未来的缓存-Caffeine 如何优雅的设计和使用缓存? Caffeine缓存 现代化的缓存设计方案 springboot使用caffeine springboot学习(十二):缓存caffeine的使用 caffeine源码分析——淘汰策略tinylfu 二分钟快速掌握Caffeine 三种填充策略:手动、同步和异步 详解 Java 中的四种引用