¶hadoop生态圈
¶hadoop生态圈图谱
¶hadoop生态圈图
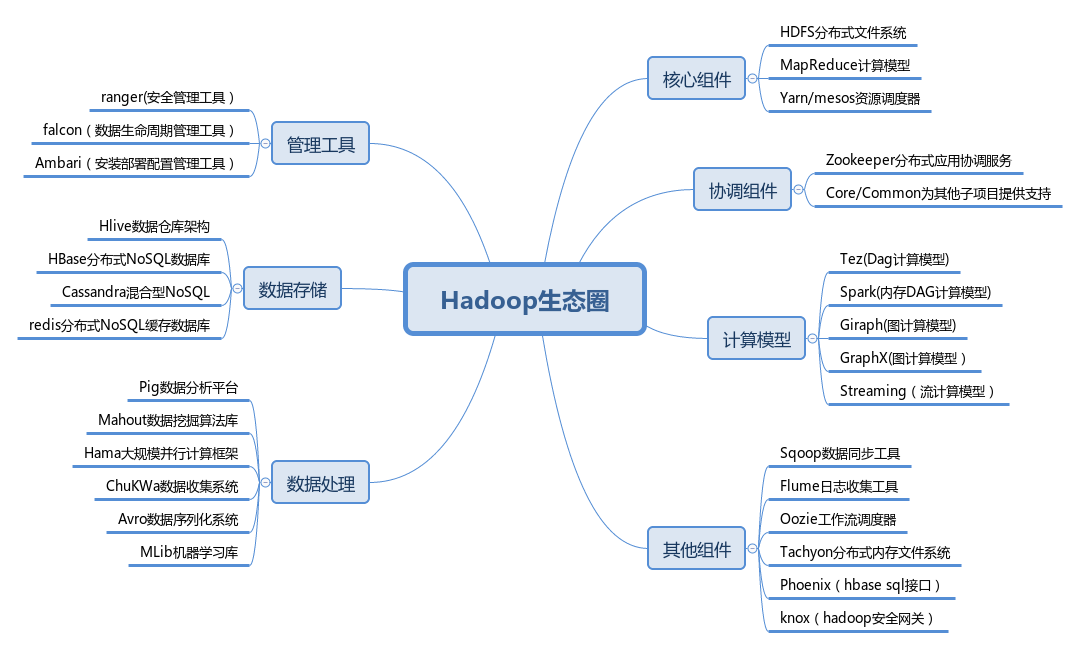
¶hadoop各个组件工作模式图

¶hadoop生态圈各个组件
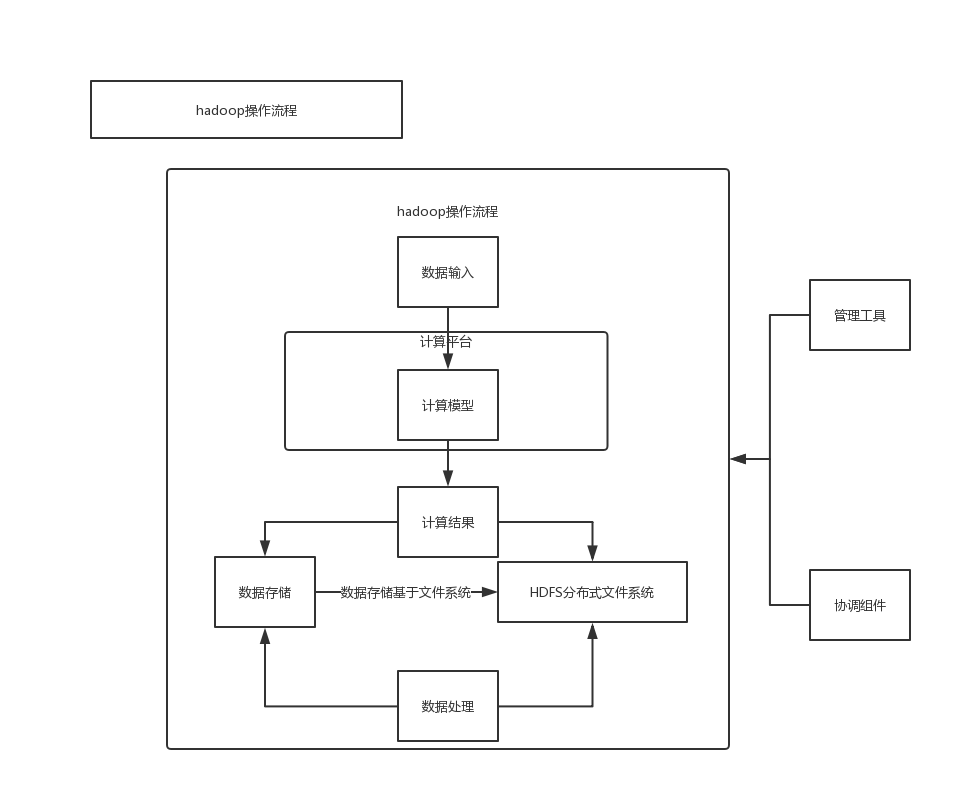
¶hadoop组件操作流程
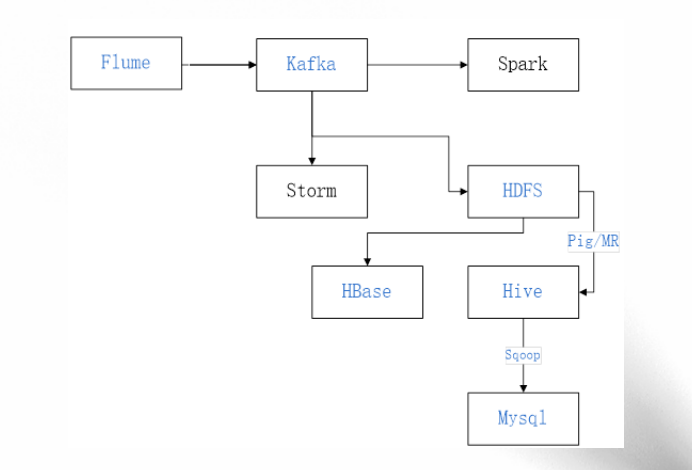
¶核心组件
- HDFS分布式文件系统
源自于Google的GFS论文,HDFS是GFS的克隆版
HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本硬件上运行。
HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
它提供了一次写入多次读取的机制,数据以块的形式分布在集群中不同的物理机器上。 - MapReduce计算模型
MapReduce是一种用于数据处理的编程模型。
源自于google的MapReduce论文,Hadoop MapReduce是google MapReduce 克隆版。
MapReduce是一种分布式计算模型,用以进行大数据量的计算。同一个程序hadoop可以运行用各种语言编写的MapReduce程序。MapReduce程序本质上是并行的,它的优势在于处理大型数据集。它屏蔽了分布式计算框架细节,将计算抽象成map和reduce两部分。
其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。
MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。 - Yarn/mesos资源调度器
Yarn是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。
Yarn是下一代 Hadoop 计算平台,Yarn是一个通用的运行时框架,用户可以编写自己的计算框架,在该运行环境中运行。
Mesos诞生于UC Berkeley的一个研究项目,现已成为Apache项目,当前有一些公司使用Mesos管理集群资源,比如Twitter。与yarn类似,Mesos是一个资源统一管理和调度的平台,同样支持比如MR、steaming等多种运算框架。
¶协调组件
- Zookeeper分布式应用协调服务
Zookeeper就是一个动物管理员(hadoop很多项目都是用动物命名的)
Zookeeper是一个分布式服务框架,主要用来解决分布式应用中经常用到的数据管理问题,如统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
Zookeeper维护一个类似文件系统的数据结构,每个子目录项都被称作znode(目录节点),它们可以存储数据。Zookeeper存储的数据量不大,主要用来保存元数据。 - Core/Common为其他子项目提供支持
¶计算模型
计算模型都是运行在yarn的,MapReduce也是一种计算模型
- Tez(Dag有向无环图计算模型)
- Spark(内存Dag计算模型)
- Giraph(图计算模型)
- GraphX(图计算模型)
- Streaming(流计算模型)
¶管理工具
- ranger安全管理工具
- falcon数据周期管理工具
- Ambari安装部署配置管理工具
Ambari可以用来快速搭建hadoop生态圈大数据组件
¶数据存储
- Hlive数据仓库
- HBase分布式NoSQL数据库
- Cassanda混合型NoSQL
- redis分布式NoSQL缓存数据库
¶数据处理
- Pig数据分析平台
- Mahout数据挖掘算法库
- Hama大规模并行计算框架
- ChuKWa数据收集系统
- Avro数据序列化系统
- MLib机器学习库
¶其他组件
- Sqoop数据同步工具
- Flume日志收集工具
- Oozie工作流调度器
- Tachyon分布式内存文件系统
- Phoenix(HBase的sql接口)
- knox(hadoop的安全网关)

